

Image Credits: Vector image designed by freepik.
Table of contents
- What is Kubernetes?
- Kubernetes components
- Kubernetes command-line tools
- Deploying a Kubernetes cluster
- Frequently asked questions (FAQ)
- Can we have more than one container in a worker node?
- Where the pods are hosted?
- What is the workload in Kubernetes?
- What is kubelet?
- What is the term “resource” used in Kubernetes?
- What Are Kubernetes watches?
- What is Kubernetes API?
- What are proxies in Kubernetes?
- What is Container Runtime Interface (CRI) in Kubernetes?
- What it mean by Kubernetes deprecating Docker?
- Which container runtimes are supported by Kubernetes?
- How to SSH into minikube virtual machine?
- How to deploy pods in minikube cluster?
- How to start a cluster with multi nodes using minikube?
- What is CoreDNS?
- Is multi-cluster supported by minikube?
- Is multi-cluster supported by kind?
- What are the pods running under “kube-system” namespace in minikube?
- What are Kubernetes objects?
What is Kubernetes?
Kubernetes is a Google-developed open source container orchestration platform for automating the deployment, scaling, and management of containerized applications across a distributed cluster of nodes. Containerized applications are those that run inside containers.
Kubernetes supports various container runtimes: Kubernetes supports multiple container runtimes, one of them being Docker, which is one of the most well-known container tools on the market.
The name Kubernetes originates from Greek, meaning helmsman or pilot. Kubernetes is often shortened to K8s, which comes from the fact that there are eight letters between the “K” and the “s.” Kubernetes has become the de facto standard for container orchestration.
Containers are a good way to bundle and run our applications. In a production environment, it’s important to keep an eye on and manage the containers that run the applications to make sure there’s no downtime. In the event that one container goes down, another needs to be started. If a system were responsible for managing this behavior, wouldn’t it make things simpler?
That’s how Kubernetes comes to the rescue! Kubernetes provides us a framework that allows us to run distributed systems in a resilient manner. It takes care of scaling and failover for our application.
When developers want to deploy an application on multiple computers, they use Kubernetes rather than deploying the application on each computer individually. Kubernetes provides an abstraction layer on top of the underlying infrastructure (computers, networks, etc.) for both users and applications. Kubernetes hides the infrastructure underneath from the applications, making development and configuration simpler. Kubernetes’ primary goal is to hide the complexity of managing a collection of containers.
 |
|
|---|---|
| Figure 1: Kubernetes provides an abstraction on top of underlying infrastructure. |
Having said that, Kubernetes enabled development teams to spend less time on technology and more time on capability.
Kubernetes provides us with:
- Service discovery: Kubernetes has the ability to expose a container by using either the DNS name or their own IP address.
- Load balancing: Kubernetes is able to load balance and distribute the network traffic to ensure that the deployment remains stable even when there is a huge volume of traffic to a container.
- Storage orchestration: Kubernetes allows us to automatically mount a storage system of our choice.
- Automated rollouts and rollbacks: Using Kubernetes, we are able to specify the desired state of our deployed containers, and it is able to transform the actual state to the desired state at a controlled rate. For instance, we might automate Kubernetes to create new containers for our deployment, delete any existing containers, and transfer all of those containers’ resources to the newly generated container.
- Automatic bin packing: We provide a cluster of nodes available to Kubernetes so that it may utilize those nodes to run containerized tasks. We inform Kubernetes of the required amount of memory and processor for each container. Kubernetes enables us to make the most efficient use of our resources by fitting containers onto our nodes.
- Self-healing: Kubernetes restarts containers that fail, replaces containers, kills containers that don’t respond to your user-defined health check, and doesn’t expose them to clients until they are ready to serve.
- Secret and configuration management: We are able to store and handle sensitive information with the help of Kubernetes. This includes passwords, OAuth tokens, and SSH keys. We can deploy and update secrets and application configuration without rebuilding our container images, and without exposing secrets in our stack configuration.
Kubernetes components
Kubernetes cluster is made up of:
- A control plane (aka master).
- A set of worker machines known as worker nodes or simply workers.
- A distributed storage system that is responsible for maintaining the cluster’s consistent state.
When we deploy Kubernetes, it creates a cluster. A Kubernetes cluster is made up of a set of machines known as nodes. The nodes can be virtual machines (VMs) or physical machines. The nodes include a master node and a set of worker nodes. The worker nodes are responsible for running containerized applications. At least one worker is present in every cluster. Our applications that are contained inside the containers. Each worker node holds one or more containers.
The worker node(s) hosts the Pods. A pod represents one or more running containers. The control plane is responsible for managing the cluster’s worker nodes as well as the Pods. The control plane generally runs across multiple nodes in production environments, which provides fault tolerance and high availability.
What is a control plane and why do we need it?
The control plane is the central nervous system of a Kubernetes cluster. It ensures that every component in the cluster is kept in the desired state.
Desired state vs. actual state: Desired state is one of the core concepts of Kubernetes. It’s the state that we want the system to be in. The desired state is defined in a Kubernetes resource. The actual state, on the other hand, is the state that the system is actually in.
Control plane receives data about internal cluster events, external systems, and third-party applications. It analyses the data, and based on that, it takes decisions and puts them into action. The control plane manages and maintains the worker nodes that hold the containerized applications.
Components of the control plane
The control plane is made up of several components. All these components run on a node called the primary node or master node.
- An API server as kube-apiserver
- A scheduler as kube-scheduler
- A controller manager as kube-controller-manager
- A persistent data store as etcd
- A cloud controller manager as cloud-controller-manager
kube-apiserver
The core of Kubernetes’ control plane is the API server called Kubernetes API. Kubernetes API acts as the interface via which the control plane communicates with the worker nodes and other external systems. An API can be anything that’s used for programmatic communication. The Kubernetes API in particular is RESTful. The command line interface, web user interface, users, and services communicate with the cluster through Kubernetes API.
The Kubernetes API lets us query and manipulate the state of API objects in Kubernetes such as Pods, Namespaces, ConfigMaps, and Events. The main implementation of the Kubernetes API server is the kube-apiserver. Since it is meant to extend horizontally, we are able to deploy many instances of the kube-apiserver in order to evenly distribute the load.
etcd (persistent data store)
Persistent data storage is provided by etcd, which is a distributed, reliable key-value store. It is a standalone open source tool, and Kubernetes communicates to it using the kube-apiserver.
It stores the configuration information that is needed by the worker nodes as well as other data that is required to manage the cluster.
kube-scheduler
kube-scheduler is responsible for allocating new pods to the worker nodes. When the pods are assigned to a new worker node, the kubelet (node agent) running on the node retrieves the pod definition from the Kubernetes API. Then, the kubelet creates the required resources and containers in accordance with the pod specification.
In other words, the scheduler is a component that runs inside the control plane and is responsible for distributing the resources and workload across the worker nodes.
kube-controller-manager
The Kubernetes controller manager is a daemon that acts as a continuous control loop in a Kubernetes cluster. A control loop is a kind of loop that does not terminate, and it monitors the current state of the cluster via calls made to the API Server, and changes the current state to match the desired state described in the cluster’s declarative configuration. The controller manager is made up of four different control loops that are referred to as controller processes. In order to achieve this goal, a controller loop is required to comprise two components:
- Snapshot of the current state of the system.
- Access to the desired state of the system.
These controller processes keep an eye on the status of the different services deployed through the API and take corrective action if the current state doesn’t match the desired state.
The controllers that ship with Kubernetes are:
- Replication controller
- Endpoints controller
- Namespace controller
- Serviceaccounts controller
Even though kube-controller-manager is composed of four separate processes, it runs as a single process in order to keep things as simple as possible.
cloud-controller-manager
The cloud-controller-manager is a separate component that connects the cluster to the API of the underlying cloud infrastructure. It runs only the controllers specific to the cloud provider, such as AWS, GCP, and so on. This way, the components interacting with our cloud provider are kept separate from the components that only interact with our cluster.
The cloud-controller-manager consists of three controller processes, which are combined into a single process to reduce complexity:
- Node controller
- Router controller
- Service controller
Kubernetes concepts
Cluster
A cluster is a collection of hosts or nodes that work together to offer computing, memory, storage, and networking resources. Kubernetes uses these resources to run the various workloads (applications).
Nodes
A single computer or host is referred to as a node. It may be a physical or virtual machine. Its primary function is to run pods. Each node in a Kubernetes cluster is responsible for running a number of Kubernetes components, including the kubelet, the container runtime, and the kube-proxy. Nodes are managed by a Kubernetes master. The nodes are Kubernetes’s “worker bees,” and they are responsible for doing all of the heavy lifting.
Workloads
An application that is being executed on Kubernetes is referred to as a workload. On Kubernetes, we will execute our workload inside of a set of pods, regardless of whether our workload consists of a single component or multiple that operate together. In Kubernetes, a Pod represents a set of running containers on our cluster.
Note that we don’t need to manage each Pod directly. Pods are are managed by controllers in the form of a control loop. A controller is responsible for monitoring the current state of a Kubernetes resource and and makes the requests necessary to change its state to the desired state.
Kubernetes comes with a number of built-in workload resources, including the following:
- Deployment
Pod
In Kubernetes, the unit of work is referred to as a pod. Each pod contains one or more containers. Containers that are contained inside pods are always scheduled together and always run on the same machine. All of the containers that make up a pod share the same IP address and port space. They connect with one another through localhost or standard inter-process communication.
In addition, all of the containers that are contained inside a pod have the ability to access shared local storage that is located on the node that is running the pod. By default, containers do not have access to either their local storage or any other storage. Volumes of storage must be mounted into each container inside the pod explicitly.
Pods are a great way to manage groups of containers that are closely related, depend on each other, and need to work together on the same host to get their job done. It is essential to keep in mind that pods are thought to be ephemeral (short-live), disposable entities that may be discarded and replaced whenever it is convenient. Any pod storage is destroyed with its pod. Every pod is given a unique identifier, also known as a UID, so that we can distinguish between them if necessary.
Labels
In Kubernetes, a label is a kind of metadata that can be attached to objects like pods and services in the form of a key-value pair. The purpose of a label is to help users identify the characteristics of objects in a way that is meaningful and relevant to them. In other words, labels can help describe meaningful and relevant information about an object. However, labels do not directly change or effect any functionality in the core system.
Having said that, users will often need Kubernetes labels in order to identify Kubernetes objects and carry out helpful activities on those items. For example, consider a set of pods running on the Kubernetes cluster. Let’s say it’s necessary for us to delete all of the pods that are associated with the development environment. There is no simple method to determine which pods suit that description if labels are not assigned to them beforehand. As a result of this, locating each pod and deleting it can become challenging and time consuming.
 |
|
|---|---|
| Figure 2: Labels in Kubernetes - Two separate environments, labeled as production and development. |
Note that the purpose of label is to identifying objects and not for attaching arbitrary metadata to objects.
Labels are intentionally designed with particular limitations in mind:
- Each label that is attached to an object has to have its own unique key.
- The label key has two parts: prefix8 and *name.
- It is not required to use the prefix.
- In the event that prefix does exist, it must be a valid DNS subdomain and is denoted by the forward slash (/), which is separated from the name.
- The prefix must be 253 characters long at most.
- Names must start and end with an alphanumeric character (a-z, A-Z, 0-9) and contain only alphanumeric characters, dots, dashes, and underscores.
- Values follow the same restrictions as names.
One of the most common ways to add labels to our resources is to add them directly to our config files. We can specify label values at metadata.lables like below:
apiVersion: v1
kind: Pod
metadata:
name: metadata-demo
labels:
environment: demo
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
The kubectl command-line interface tool is the alternative method for working with labels. This comes in helpful when making minor adjustments to your resources. However, it is vital to keep in mind that the modifications we make will not be automatically reflected back to the configuration files we use.
To add a label to an existing resource, we can use the following command:
# It creates a label “group” with a value of “temp”
kubectl label pod/metadata-demo group=temp
To remove the label, use this command:
kubectl label pod/metadata-demo group-
Label selectors
Label selectors provide us the ability to filter objects based on their labels. For example, we can filter out all of the objects that have the label env: production.
Annotations
Annotations are another type of metadata we can use in Kubernetes. Like labels, annotations are key-value pairs. Annotation lets us associate arbitrary metadata with Kubernetes objects. Labels, on the other hand, can be used in the process of identifying and selecting items, but annotations cannot. Annotations are meant to be used to store any information about an object that doesn’t identify it.
Similar to labels, annotations can be added in a number of different methods, the most common of which are via config files or the kubectl command line.
For example, here’s the configuration file for a Pod that has the annotation imageregistry: https://hub.docker.com/:
apiVersion: v1
kind: Pod
metadata:
name: annotations-demo
annotations:
imageregistry: "https://hub.docker.com/"
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Kubernetes command-line tools
The command-line tools for Kubernetes are as follows:
kubectl
The Kubernetes command-line tool is known as kubectl. It allows us to run commands against Kubernetes clusters. We can use kubectl to:
- Deploy applications
- Inspect and manage cluster resources
- View logs
Syntax:
kubectl [command] [type] [name] [flags]
To verify that your cluster is working, use the following command:
kubectl cluster-info
Kubernetes control plane is running at https://127.0.0.1:50918
CoreDNS is running at https://127.0.0.1:50918/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
The above output of kubectl cluster-info command indicates that the control plane is active and responding to requests.
Now use the kubectl command to list all nodes in our cluster:
kubectl get nodes
The output will resemble what is shown below:
NAME STATUS ROLES AGE VERSION
minikube Ready control-plane 48d v1.24.3
The above output shows a cluster with single node.
Note: Everything in Kubernetes is represented as an object, which can be obtained and manipulated via the RESTful API. The
kubectl getcommand retrieves a list of objects of the specified type from the API. In the above case, it’s of type “node”.
To see more detailed information about an object, we use the following command:
kubectl describe node <name of the node>
Because it is such a large output, I have chosen to exclude the actual output that the describe command generates.
To check the status of the pods for all the namespaces
kubectl get pods --all-namespaces
The output look like the ones shown below:
NAMESPACE NAME READY STATUS RESTARTS AGE
default nicepod 1/1 Running 3 (45m ago) 45d
kube-system coredns-6d4b75cb6d-nsx8w 1/1 Running 4 (45m ago) 45d
kube-system etcd-minikube 1/1 Running 5 (45m ago) 45d
kube-system kube-apiserver-minikube 1/1 Running 5 (45m ago) 45d
kube-system kube-controller-manager-minikube 1/1 Running 6 (45m ago) 45d
kube-system kube-proxy-8fhb9 1/1 Running 4 (45m ago) 45d
kube-system kube-scheduler-minikube 1/1 Running 6 (45m ago) 45d
kube-system storage-provisioner 1/1 Running 16 (45m ago) 45d
kubernetes-dashboard dashboard-metrics-scraper-78dbd9dbf5-9xnmp 1/1 Running 3 (45m ago) 45d
kubernetes-dashboard kubernetes-dashboard-5fd5574d9f-bpqrz 1/1 Running 8 (45m ago) 45d
To check the physical and internal IP details of all the pods, use the following command:
kubectl get pods -n <namespace> -o wide
kind
kind lets us run Kubernetes on our local computer. This tool requires that we have Docker installed and configured. In other words, it runs local Kubernetes clusters using Docker container “nodes”. kind was primarily designed for testing Kubernetes, but it can also be used for local development or CI.
It has both support for:
- Multi-cluster
- Multi-node
It puts the cluster into Docker containers. This leads to a significantly faster startup speed compared to spawning a VM. However, creating a cluster is very similar to minikube’s approach.
Installation
Refer here to install kind.
Create a cluster
To create a cluster:
kind create cluster
This will bootstrap a Kubernetes cluster using a pre-built node image. The node image is a Docker image for running nested containers, systemd, and Kubernetes components. Prebuilt images are hosted at kindest/node. To specify another image use the --image flag as shown below:
kind create cluster --image <>
Note that kind has the ability to load our local images directly into the cluster. This saves us from having to set up a registry and push our image every time we want to try out our changes.
Using the following command, we can able to load our local images:
kind load docker-image my-app:latest
By default, the cluster will be given the name kind. Use the --name flag to assign the cluster a different context name.
kind create cluster --name kind-2
Interacting with the cluster
After creating a cluster, you can use kubectl to interact with it by using the configuration file generated by kind. By default, the cluster access configuration is stored in ${HOME}/.kube/config if $KUBECONFIG environment variable is not set.
To list the clusters created using kind:
kind get clusters
In order to interact with a specific cluster, we only need to specify the cluster name as a context in kubectl:
kubectl cluster-info --context kind-<name>
Deleting a cluster:
kind delete cluster --name <name>
Loading an image into the cluster:
kind load docker-image my-custom-image-0 my-custom-image-1 --name kind-2
Note that --name flag is optional if the cluster created wit default name i.e., kind.
minikube
Like kind, minikube is a tool that enables us to run Kubernetes on a local computer. In order for us to get a feel for Kubernetes, minikube runs a Kubernetes cluster with a single node on each of our individual computers (including Windows, macOS, and Linux PCs). It does this by spawning a VM that is essentially a single-node K8s cluster.
Spawning: Spawning in computing refers to a function that loads and executes a new child process.
Note that minikube does not support multi-cluster; however, it supports multi-node cluster.
Minimum requirements to install minikube
- 2 CPUs or more
- 2GB of free memory
- 20GB of free disk space
- Container or virtual machine manager, such as:
- Docker
- Hyperkit
- Hyper-V
- KVM
- Parallels
- Podman
- VirtualBox
- VMware Fusion/Workstation
minikube with Docker: If we choose Docker as the container or VM manager for minikube, minikube runs as a Docker container as shown below: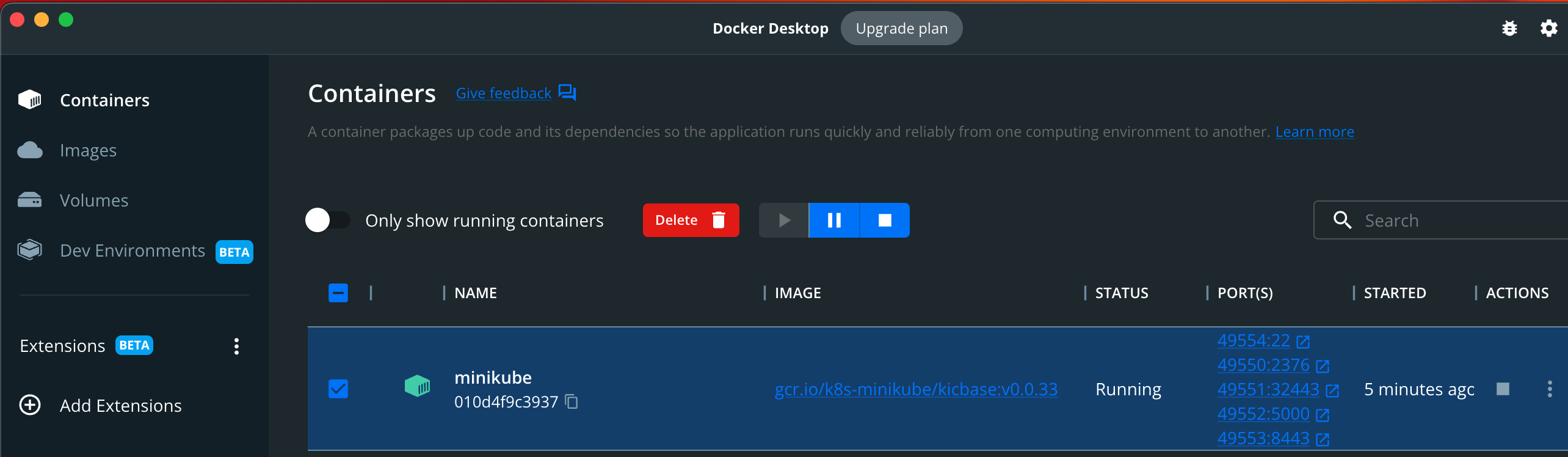
Figure 1: minikube custer runs as a Docker container.
To install the latest minikube stable release on on x86-64 macOS using Homebrew:
brew install minikube
Start our cluster
To start a single-node cluster:
minikube start
minikube dashboard
minikube has integrated support for the web-based dashboard. To access the web-based dashboard:
minikube dashboard
This will enable the dashboard add-on, and open the proxy in the default web browser. If we we do not want to launch a web browser, we can instruct the dashboard command to instead merely output a URL as shown below:
minikube dashboard --url
We can use dashboard to:
- Deploy containerized applications to a Kubernetes cluster.
- Troubleshoot your containerized application.
- Manage the cluster resources.
- Get an overview of applications running on your cluster.
- Creating or modifying individual Kubernetes resources such as Deployments, Jobs, DaemonSets, etc.
kubeadm
We can use the kubeadm tool to create and manage Kubernetes clusters. It performs the tasks required to get a minimum viable, secure cluster up and running in a manner that is friendly to users.
Deploying a Kubernetes cluster
There are many different ways that Kubernetes cluster can be deployed:
- Installing and configuring a full-fledged Kubernetes cluster with multiple nodes.
- Using the built-in Kubernetes cluster in Docker Desktop.
- Running a local cluster using minikube CLI
Installing and configuring a full-fledged Kubernetes cluster with multiple nodes
It is not an easy job to set up a full-fledged Kubernetes cluster with multiple nodes, particularly if we are not familiar with Linux or network management. A proper Kubernetes installation involves the use of many physical or virtual machines and requires proper network setup to allow all containers in the cluster to communicate with one another.
A full-ledged Kubernetes cluster can be installed:
- On our our local machines.
- On virtual machines provided by cloud providers like Google Compute Engine, Amazon EC2, Microsoft Azure, and so on.
- On the other hand, almost all cloud service providers now offer managed Kubernetes services, which saves us the trouble of installing and managing it. A brief list of the services offered by the most popular cloud providers follows: Google offers GKE, Amazon has EKS, Microsoft has AKS, and so on.
Keep in mind that installing and managing Kubernetes ourselves is a much more complicated task than just using it, especially before we know a lot about its architecture and how it works.
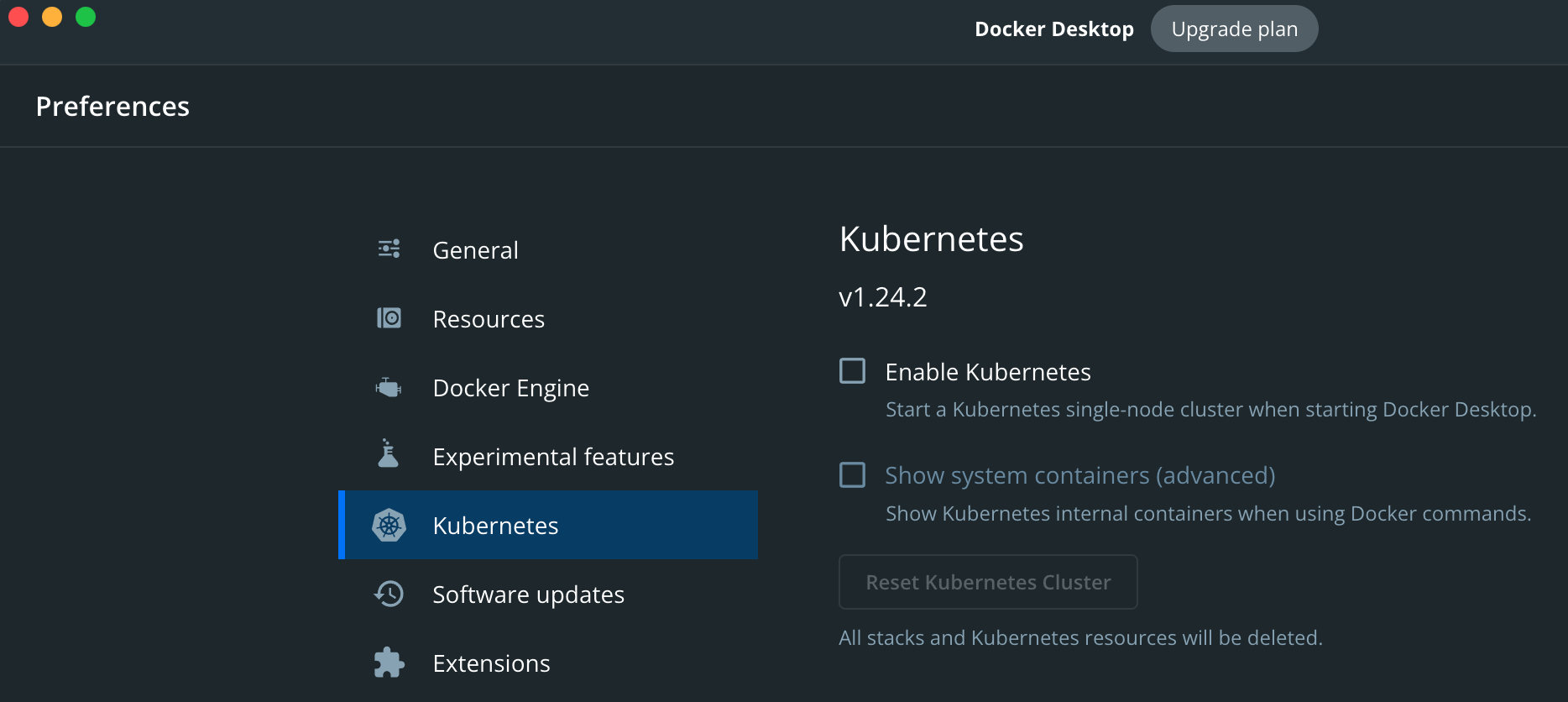
Using the built-in Kubernetes cluster in Docker Desktop
Docker Desktop for macOS and Windows comes preinstalled with a single-node Kubernetes cluster that can be enabled by going into the Settings dialog box as shown in Figure 2 below.
 |
|
|---|---|
| Figure 2: Kubernetes preinstalled with Docker Desktop. |
Running a local cluster using minikube CLI
minikube, which is a command-line tool that is maintained by the Kubernetes community, is yet another method that can be used to create a Kubernetes cluster. It enables us to run Kubernetes on a local computer. In order for us to get a feel for Kubernetes, minikube runs a Kubernetes cluster with a single node on each of our individual computers (including Windows, macOS, and Linux PCs).
Installing minikube CLI
minikube CLI supports macOS, Linux, and Windows. It just consists of a single executable binary file, which can be found in the minikube repository on GitHub. More information on how to install it for various operating systems can be found here.
Packing applications in containers
Applications come in many different shapes and sizes. They begin by taking input, manipulating the data, and then providing the results. Application programs normally have a language runtime, libraries including external libraries, configurations, and source code as their primary components.
There are many ways to deploy these applications as a whole:
- Configuration management systems: We can use configuration management systems like Puppet or Ansible, which use code to install, run, configure, and update applications.
- Omnibus package: It’s an effort to include everything that the program requires in a single file as much as possible. For example, a Java omnibus package would include the Java runtime as well as all the JAR files for the application.
From an operational point of view, we need to be able to handle not just all of these various kinds of packages or applications, but also a fleet of servers on which to host them. These servers need to be provisioned, networked, deployed, configured, kept up-to-date with security patches, monitored, and managed. This all takes a significant amount of time, technical expertise, and effort just to provide a platform to run applications on.
Kubernetes configuration
Frequently asked questions (FAQ)
Can we have more than one container in a worker node?
Yes. Each worker node holds one or more containers.
Where the pods are hosted?
The worker node(s) hosts the Pods.
What is the workload in Kubernetes?
A workload is an application running on Kubernetes. On Kubernetes, our workload is always run within a collection of pods, regardless of whether it consists of a single component or several that work together.
What is kubelet?
Every worker node has a node agent called Kubelet that it runs. It oversees communicating with the master components and manages the running pods. Here are the key things that the Kubelet does:
- Receiving pod specs
- Downloading pod secrets from the API server
- Mounting volumes
- Running the pod’s containers (via the configured runtime)
- Reporting the status of the node and each pod
- Running the container startup, liveness, and readiness probes
What is the term “resource” used in Kubernetes?
Anything we create in a Kubernetes cluster is considered a resource: deployments, pods, services and so on.
What Are Kubernetes watches?
Getting the state of the resources using the Kubernetes API at a certain point in time isn’t always enough when working with Kubernetes clusters, because these clusters are highly dynamic in nature. In most cases, we also want to keep an eye on these resources and track events as they happen.
Regular pooling is one strategy that may be used. However, polling puts us at risk of missing events that take place in the interval between polling cycles. Additionally, when the number of resources that need to be monitored rises, this strategy will not scale up very effectively.
TODO - How it’s addressed by watches?
What is Kubernetes API?
TODO
What are proxies in Kubernetes?
KubeProxy is a network proxy that is implemented as a component of the Kubernetes Service. It runs on every node in the cluster. It maintains a record of the network rules that govern communication between pods located within and outside of the cluster. In other words, these network rules allow network communication to our Pods from network sessions inside or outside of our cluster.
To put it simply, kube-proxy on each node takes care of redirecting traffic to the correct pod.
Modes
There are two kube-proxy modes:
- IPTABLES (default)
- IPVS (IP Virtual Server) - It’s an advanced configuration used in a cluster with thousands of servers and offers high network performance.
What is Container Runtime Interface (CRI) in Kubernetes?
In the early days of Kubernetes, the Docker Engine was the only container runtime that was supported. After some time, more container runtimes were made available, such as rkt and hypernetes, and each container runtime has it own strengths. It became evident that users of Kubernetes want a choice of runtimes that would work best for them.
The Container Runtime Interface (CRI) was released (1.5 release) to allow that flexibility. It’s a plugin interface which enables kubelet to use a wide variety of container runtimes without the need to recompile. For more information about CRI, refer here.
What it mean by Kubernetes deprecating Docker?
Docker as an underlying container runtime is being deprecated in favor of runtimes that use the Container Runtime Interface (CRI) created for Kubernetes. Note that Docker-produced images will continue to work in our cluster with all runtimes normally. Docker is still a useful tool for building containers, and the images that are produced as a result of executing docker build can still run in our Kubernetes cluster.
The container runtime is responsible for pulling and running our container images. Docker is a popular choice for that runtime, but Docker was not designed to be embedded inside Kubernetes, and that causes a problem.
Docker is not just a single piece; rather, it refers to a whole technology stack. It includes a component known as “containerd,” which is a high-level container runtime by itself. Also, Docker has a lot of UX enhancements that make it really easy for humans to interact with when we are doing development work. However, these UI enhancements aren’t required for Kubernetes, , because it isn’t a human.
Kubernetes cluster has to use another tool called Dockershim to get at what it really needs, which is containerd. Kubernetes support for Docker via dockershim is now removed.
What is dockershim in Kubernetes and why was it removed from Kubernetes?
The introduction of the Container Runtime Interface (CRI) was a great step forward in providing us with the flexibility to use any container runtime of our choice, but it did introduce a problem: Docker Engine was being used as a container runtime well before CRI was introduced, and Docker Engine is not compatible with CRI.
What is the term “shim” in computing? A shim is a small library that transparently intercepts and modifies calls to an API, usually for compatibility purposes.
To solve this issue, a small software shim called dockershim was introduced as part of the kubelet component specifically to fill in the gaps that exist between Docker Engine and CRI, allowing cluster operators to continue using Docker Engine as their container runtime largely uninterrupted.
However, this little software shim was never intended to be a long-term solution. Over the years, dockershim’s existence has made the kubelet much more complicated than it needs to be. Unfortunately, this caused some concern among the community since the deprecation notice wasn’t presented as clearly as it should have been.
Kubernetes has published a blog post that includes a frequently asked questions section in an effort to allay the concerns of the community and clear up any misunderstandings on what Docker is and how containers function inside Kubernetes.
Note that Docker is not going away, either as a tool or as a company.
Which container runtimes are supported by Kubernetes?
In its early stages, Kubernetes only provided support for the Docker container runtime engine. However, it is not the case any more. Kubernetes now provides support for a variety of runtimes:
- Docker via dockershim
- rkt
- CRI-O
- Frakti
- rktlet
- CRI-containerd
How to SSH into minikube virtual machine?
Use the following command to SSH into minikube VM:
minikube ssh
uname -a
logout
How to deploy pods in minikube cluster?
Let’s create a pod and expose it on port 80:
kubectl create deployment hello --image=docker.io/nginx:1.23
kubectl expose deployment hello --type=NodePort --port=8080
The create deployment command will create a deployment, which will then create a pod with one container running the given image. We can use the following command to get the status of the deployment:
kubectl get deploy
To see the pod that the deployment created, run the following command:
kubectl get po
The output looks like the pictures below:
NAME READY STATUS RESTARTS AGE
echo-5b565549d6-6rrv2 1/1 Running 1 (5h21m ago) 8h
hello-795877ccfc-245tt 1/1 Running 1 (5h21m ago) 8h
nicepod 1/1 Running 4 (5h21m ago) 46d
Note that the reason the Pod has two sets of random characters in the name is that the deployment has created a ReplicaSet to perform the actual pod management, and the ReplicaSet created the Pod.
When the service is exposed as type NodePort, it is available to the host on some port. But we did not run the pod on the 8080 port. In the cluster, ports are mapped. We need the cluster IP and the exposed port in order to get to the service.
Use the following command to find the cluster IP:
minikube ip
To check if the pod is created, use the following command:
kubectl get pods
How to start a cluster with multi nodes using minikube?
We can start a cluster with multi nodes in the driver of our choice. In the below, we are starting a cluster with 2 nodes:
minikube start --nodes 2 -p multinode-demo
We can also check the status of your nodes:
minikube status -p multinode-demo
Output:
multinode-demo
type: Control Plane
host: Running
kubelet: Running
apiserver: Running
kubeconfig: Configured
multinode-demo-m02
type: Worker
host: Running
kubelet: Running
What is CoreDNS?
CoreDNS is a flexible DNS server written in the Go programming language that can serve as the Kubernetes cluster DNS. Since it is written in Go, the top-end performance is also not good. But it’s not a problem because we don’t use CoreDNS in places where we need really fast performance.
It uses a plugin-based architecture, which is easily extended. To support different cloud-native stacks, for example. It also supports DNS over TLS (DoT) and DNS over gRPC.
It has native support for service discovery for Kubernetes. It is integrated with etcd and cloud vendors (e.g., AWS’s Route 53). It has support for Prometheus metrics. It is also capable of forwarding to a recursive DNS server, and this is really important because it doesn’t actually have the capability to act as a full-service DNS recursive itself.
CoreDNS vs. kube-dns
- An easily extensible plugin-architecture with a rich set of plugins
- It is simple, with fewer moving parts (single executable and process), and all written in Go.
- Customizable DNS entries in and out of the cluster domain. For example, we can add static DNS data within the cluster domain.
- Experimental server-side search path to reduce query volume.
Is multi-cluster supported by minikube?
No. Note that minikube does not support multi-cluster; however, it supports multi-node cluster.
Is multi-cluster supported by kind?
Yes. Note that kind does support both multi-cluster and multi-node cluster.
What are the pods running under “kube-system” namespace in minikube?
The following pods are running under “kube-system” namespace:
- coredns
- etcd-minikube
- kube-apiserver-minikube
- kube-controller-manager-minikube
- kube-proxy
- kube-scheduler-minikube
- storage-provisioner
What are Kubernetes objects?
Kubernetes objects are persistent entities in the Kubernetes system. Kubernetes uses these entities to represent the state of our cluster. Specifically, they can describe:
- What containerized applications are running (and on which nodes)
- The resources available to those applications
- The policies around how those applications behave, such as restart policies, upgrades, and fault-tolerance
Once we’ve create the object, Kubernetes will keep working to make sure that object exists. By creating an object, we tell the Kubernetes system how we want our cluster’s workload to look. This is the desired state of our cluster.
Comments