

Table of contents
- Introduction to collections
- Collections in Scala
- Frequently asked questions (FAQ)
- What is “InPlace” transformation operation?
- What are transformer methods?
- What is collection buffer?
- What is collection builder?
- What is persistent data structure?
- What are the benefits of using Vector in Scala over List or other data structures?
- What is trie data structure?
- What is identity function?
Introduction to collections
A collection is an object in programming that groups multiple elements into a single unit. It’s comparable to a container that can hold various items. A collection has an underlying data structure that is used to store, manipulate, and retrieve aggregate data in an efficient manner. When collections are used, readability and maintenance of the code are enhanced.
Collections in Scala
Scala has a very rich collections library, located under the scala.collection package. There are two types of collections in Scala:
- Mutable collections
- Immutable collections
All collection classes are found in the following packages:
scala.collectionscala.collection.immutablescala.collection.mutable
Scala collections vs Java collections: Scala collections are notably distinct from Java collections. For example, the Scala
Listclass differs significantly from the JavaListclass, including the immutable nature of the ScalaList.
Mutable collections
A mutable collection can be modified or extended in place. This means that we can modify, add, or remove elements from a collection with side effects. All mutable collection classes are present in the scala.collection.mutable package.
Immutable collections
In contrast, immutable collections never change. There are still operations that simulate additions, deletions, and updates, but each of these operations returns a new collection and leaves the original collection unchanged. All immutable collections are present under scala.collection.immutable.
The collections in scala.collection are supertypes of scala.collection.mutable and scala.collection.immutable. The base operations are added to the types in the scala.collection package, while the immutable and mutable operations are added to the types in the other two packages.
A high-level view of the Scala collections
TODO
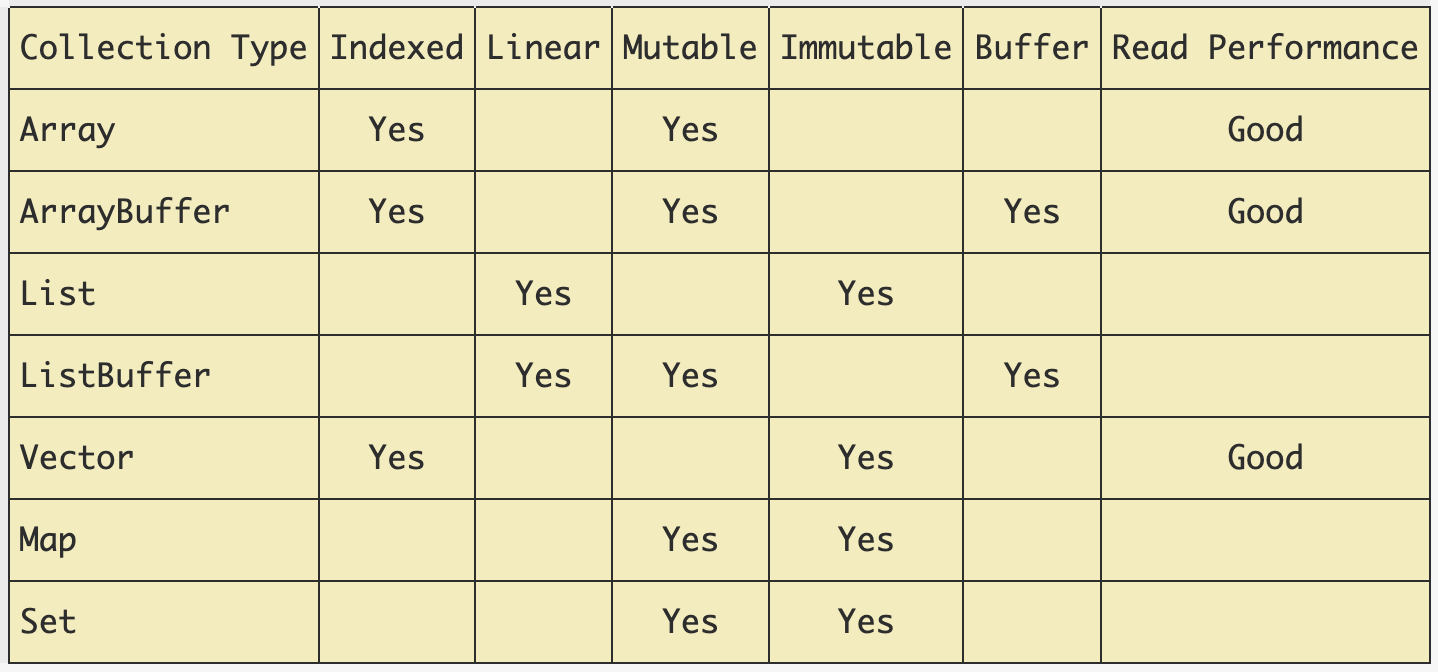
Collections table
Frequently asked questions (FAQ)
What is “InPlace” transformation operation?
Instead of always returning a new collection after a map or filter operation, mutable collections have a couple of new operations (filterInPlace and mapInPlace) that let us change the elements right where they are (in-place). These new operations change the source collection.
val buf1 = ArrayBuffer(0, 1, 2, 3, 5, 6, 8, 9)
buf1.filterInPlace(_ % 2 == 0)
buf1 // ArrayBuffer(0, 2, 6, 8)
val buf2 = ArrayBuffer(0, 1, 2, 3, 5, 6, 8, 9)
buf2.mapInPlace(_ * 2)
buf2 // ArrayBuffer(0, 2, 4, 6, 10, 12, 16, 18)
What are transformer methods?
Transformer methods are collection methods that transform an input collection into a new output collection based on an algorithm we provide.
Note that these transformations create copies of the collection while leaving the original untouched. This implies that if the original array is still in use, its contents will not be affected by the transform.
The transformer methods are as follows:
mapfilterreverse
What is collection buffer?
Buffers are used to create sequences of elements incrementally by appending, prepending, or inserting new elements. A buffer can grow and shrink. Having said that, buffers are mutable.
Scala has buffers such as:
ArrayBufferListBuffer
What is collection builder?
A builder is a simplified form of a Buffer that is limited to generating its assigned collection type and only performing append operations. This is most useful for constructing immutable collections where we cannot add or remove elements once the collection has been constructed.
To construct a builder for a certain collection type, use the type’s newBuilder method and pass in the element type as shown below. Invoke the builder’s result method to convert it back into the final type (in this case Array).
$ val af = Array.newBuilder[Int]
af: collection.mutable.ArrayBuilder[Int] = ArrayBuilder.ofInt
$ af += 4
$ af += 7
$ af.result
res1: Array[Int] = Array(4, 7)
Builder vs buffer (TODO)
Difference 1: Unlike with buffers, a builder knows its immutable counterpart:
Lets first construct an array collection using builder:
$ val af = Array.newBuilder[Int]
af: collection.mutable.ArrayBuilder[Int] = ArrayBuilder.ofInt
Now, let’s the know the type of the collection using getClass() method. The type shows below is a mutable one.
$ af.getClass
res1: Class[T] = class scala.collection.mutable.ArrayBuilder$ofInt
Let’s append a value and see the type again:
$ af += 6
res2: collection.mutable.ArrayBuilder[Int] = ArrayBuilder.ofInt
$ af.getClass
res3: Class[T] = class scala.collection.mutable.ArrayBuilder$ofInt
Now, let’s freeze the collection using result method and check the type again. Type is implicitly converted to its immutable counterpart.
$ af.result
$ af.getClass
res68: Class[T] = class scala.collection.mutable.ArrayBuilder$ofInt
What is persistent data structure?
A persistent data structure, also known as a non-ephemeral data structure, is a data structure that always preserves its prior state when it is updated. These data structures are essentially immutable, since their operations do not alter the structure in-place, but rather always result in a new structure that has been modified. Having said that, all immutable data structures or collections are all persistent.
Consider the following examples. I have used ammonite REPL to demostrate persistent data structure. Therefore, it displays the ‘@’ prefix. We created a list of numbers and used a filter method to choose just the even elements. As seen in the example below, the updated list produces a new list named res142. It does not update the original list - we checked the same by printing the original list.
@ val numSeq: List[Int] = List(10, 7, 21, 8, 3, 17)
numSeq: List[Int] = List(10, 7, 21, 8, 3, 17)
@ numSeq.filter(_ % 2 == 0)
res142: List[Int] = List(10, 8)
@ print(numSeq)
List(10, 7, 21, 8, 3, 17)
What are the benefits of using Vector in Scala over List or other data structures?
Vector is an immutable data structure introduced in version 2.8 of the Scala to address the inefficiencies of random access in other existing data structures. Vector is a persistent data structure using structural sharing. Random access is much better with vector, especially when the collection is big.
Implemention
Vector extends AbstractSeq and IndexedSeq, thus it provides constant-time (O(1)):
- Element access
- Lenght computation
Vector is currently the default implementation of immutable IndexedSeq. Vector is implemented as a base-32 integer trie. There are 0 to 32 (25) nodes at the root level, and there can be another 32 nodes connecting to each node at the root level. Thus, the second level can accommodate a maximum of 32*32 (210) elements. Similarly, the third level will have 32*32*32 (215) elements, so and so forth. Thus, a Vector of five levels can hold up to 230 elements. Accessing items from such a large collection requires traversing just five layers of nodes, making the process effectively constant time.
Performance
For head access and iteration algorithms, a linear sequence collection will provide a little advantage over an indexed sequence. For all other purposes, an indexed sequence will perform much quicker, particularly in large collections.
Prepend and append
As stated above, Vector is a persistent data structure using structural sharing. This method makes the append/prepend process almost as quick as any mutable data structure. When a new element is added by appending or prepending, the structure is modified via structure sharing and a new Vector is returned.
Random access and random updates
When it comes to random access and random updates, Vector excels in comparison to all other immutable collections. Due to its implementation of a trie data structure, accessing an element at any place in the tree involves traversing just a few levels and branches.
Head and tail access
Head and tail element access is a further common procedure. As expected, accessing the beginning and end elements of an indexed tree data structure is a quick process. Note that tail command returns an iterable that contains all the elements without the first element.
Iteration
Some algorithms need iterating over all collection components. Although traversing all of a Vector’s elements is somewhat more complex than traversing a linked list.
What is trie data structure?
Trie (to be pronounced as “try”) is an ordered tree data structure used for storing and searching a specific key from a set. A trie is also called a digital tree or prefix tree, which is a type of k-ary search tree. These keys are most often strings.
k-ary tree: An m-ary tree (also known as n-ary, k-ary, or k-way tree) is a rooted tree in graph theory in which each node has no more than
mchildren. For example, a binary tree has a max of 2 children (m = 2), and a ternary tree is another case with m = 3, which limits its children to three.
What is identity function?
An identity function is a basic function that takes one argument and the only thing it does is return the same argument value, unchanged i.e., f(x) = x. In other words, it’s a function in which the output is the same as the input. The identity function is also known as an identity map or identity relation.
Just like zero is a neutral value for additions, an identity function is a nuetral value for higher-order-functions.

Comments