

Writing in progress: If you have any suggestions for improving the content or notice any inaccuracies, please email me at [email protected]. Thanks!
The necessity for data distribution over several computers arises from either the data being too massive to store on a single machine or the computation being too long to accomplish on a single machine.
Spark architecture
Spark is built on a master-slave architecture, which we refer to as the Spark cluster. Spark cluster is made up of one master node and one or more worker nodes. Each worker node has at least one executor.
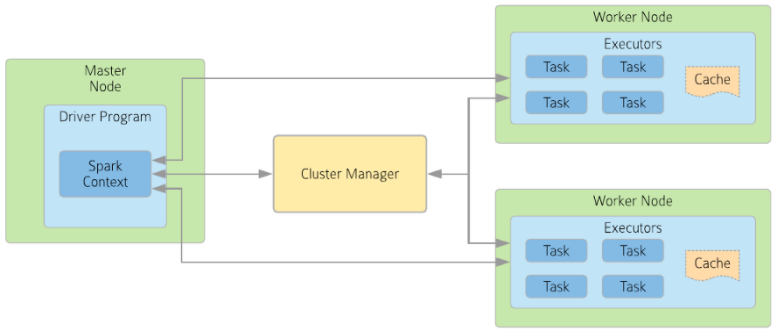 |
|
|---|---|
| Apache Spark Architecture. |
Note: From Spark 2.0 onwards we can access SparkContext object through SparkSession.
Spark driver
The Spark driver is a Java process that runs the main() function of the user program. In other words, the user program’s main() function executes in the driver process. It runs on the master node of the Spark cluster. It is the core of a Spark Application and stores all relevant information during the application’s lifetime. When we’re working with a Spark shell, the driver is part of the shell.
The driver is responsible for:
- Maintaining information about the Spark application.
- Responds to user’s program or input.
- Analyzing, distributing, and scheduling work (as tasks) across executors.
Executor
An executor resides in the worker node, and each worker node consists of one or more executors. Executors are responsible for running one or more tasks. Executors are launched at the start of a Spark application in coordination with the cluster manager. The driver launches and removes executors dynamically as needed.
Each executor is responsible for:
- Executing tasks assigned to it by the driver and reporting the status of the computation to the driver.
- Caching (in memory) or persisting (on disk) the data in the worker node.
Cluster manager
The cluster manager controls physical machines and allocates resources such as CPU, memory, and so on to Spark applications.
Cluster manager types
Apache Spark currently supports the following cluster managers:
- Standalone - a basic cluster manager included with Spark that makes it simple to build up a cluster.
- Hadoop YARN - the resource manager in Hadoop 2 and 3.
- Kubernetes - an open-source system for automating deployment, scaling, and management of containerized applications.
Local mode
Spark features a local mode in addition to its cluster mode. In local mode, the driver and executors run as threads on our own machine rather than as part of a cluster.
Spark’s APIs
Spark has two core sets of APIs:
- Low-level APIs
- High-level APIs
Partitions
In order to enable each executor to run in parallel, Spark splits the data into chunks called partitions. A partition is a collection of rows that are stored on a single physical machine in a Spark cluster. The number of executors and partitions influences Spark’s parallel processing capability.
- Many executors but only one partition = No parallism.
- Many partitions but only one executor = No parallism.
- Many executors with more than one partition = Parallism.
It is important to note that with DataFrames, we do not (for the most part) manually manipulate partitions. We merely specify high-level data transformations in the physical partitions. Spark determines how the tasks will be executed in parallel on the cluster.
Resilient Distributed Datasets (RDDs)
Spark is built around the concept of a resilient distributed dataset (RDD), which is a fault-tolerant collection of data that can be processed in parallel. There are two ways to create RDDs:
- Parallelizing an existing collection in our driver program
- Referencing a dataset in an external storage system such as a shared filesystem, HDFS, Amazon S3, etc.
What is fault tolerance in Spark RDD?
Fault refers to failure or defect or flaw. Fault tolerance is the ability of a system to continue working normally in the event of the failure of one or more of its components.
RDDs have the capability of automatically recovering from failures. Traditionally, distributed computing systems have provided fault tolerance through data replication or checkpointing. However, Spark uses a different approach called “lineage.” In data-intensive applications, lineage-based recovery is much more efficient than replication. It saves both time (since writing data over the network takes significantly longer than writing it to RAM) and memory space.
The operations carried out in an RDD are a set of Scala functions that are run on that partition of the RDD. This set of operations is combined to form a DAG. RDD tracks the graph of transformations (in DAG) that was used to build it and reruns these operations on base data to reconstruct any lost partitions.
Transformation
On RDDs, Spark uses two types of operations: transformation and action. Transformation is an operation that produces new RDD from the existing RDDs. Since RDDs are immutable in nature, each transformation operation always results in a new RDD instead of changing an existing one. Having said that, it takes RDD as input and produces one or more RDD as output.
Because RDD is immutable, Spark generates an RDD lineage that will be used to perform transformations on base data to recover any lost RDD. Also, it’s important to note that transformations are lazy. This means Spark will not act on transformations until we call an action.
Let’s do a simple transformation to identify all the even integers in our current DataFrame.
>>> nums = spark.range(5)
>>> mums.collect()
[Row(id=0), Row(id=1), Row(id=2), Row(id=3), Row(id=4)]
>>> even_nums = nums.where("id % 2 = 0")
>>> even_nums.collect()
[Row(id=0), Row(id=2), Row(id=4)]
Types of transformations
There are two types of transformations:
- Narrow dependencies aka narrow transformation
- Wide dependencies aka wide transformation
Narrow transformation
Transformations with narrow dependencies have each input partition contributing to just one output partition.
Wide transformation
Multiple input partitions contribute to many output partitions in a wide dependency style transformation. Wider transformations are the result of the groupByKey and reduceByKey functions, which compute data that spans many partitions. This type of transformation is also known as “shuffle transformations” since it shuffles the data. Wider transformations are more costly than narrow transformations due to shuffling.


Comments