Table of contents
Apache Pinot’s file system
Let’s first briefly discuss Pinot’s file system. The file system is an abstraction layer that allows users to store and read data in a data layer of their choice for real-time and offline segments. Pinot uses distributed file systems (DFS). Pinot supports the following distributed file systems:
- Amazon S3
- Google Cloud Storage
- Azure Data Lake Storage
- HDFS
By default, Pinot doesn’t have a storage layer, so if the system crashes, none of the data that was sent will be saved. To store the generated segments permanently in a local or distributed file system, we will have to change how the controller and server are configured to add deep store.
Deep store: The deep store is the permanent store for segment files. It is used to make backups and get them back (restore). A cluster’s new server nodes will get a copy of the segment files from the deep store. If the local segment files on a server get damaged in some way, a new copy will be pulled down from the deep store when the server is restarted. Note that the deep store stores a compressed version of the segment files, and it usually doesn’t have any indexes. These compressed files can be kept on a local or a distributed file system.
Importing or ingesting data into Apache Pinot
The following Pinot architectural diagram shows how batch and real-time ingestions use different data flows:
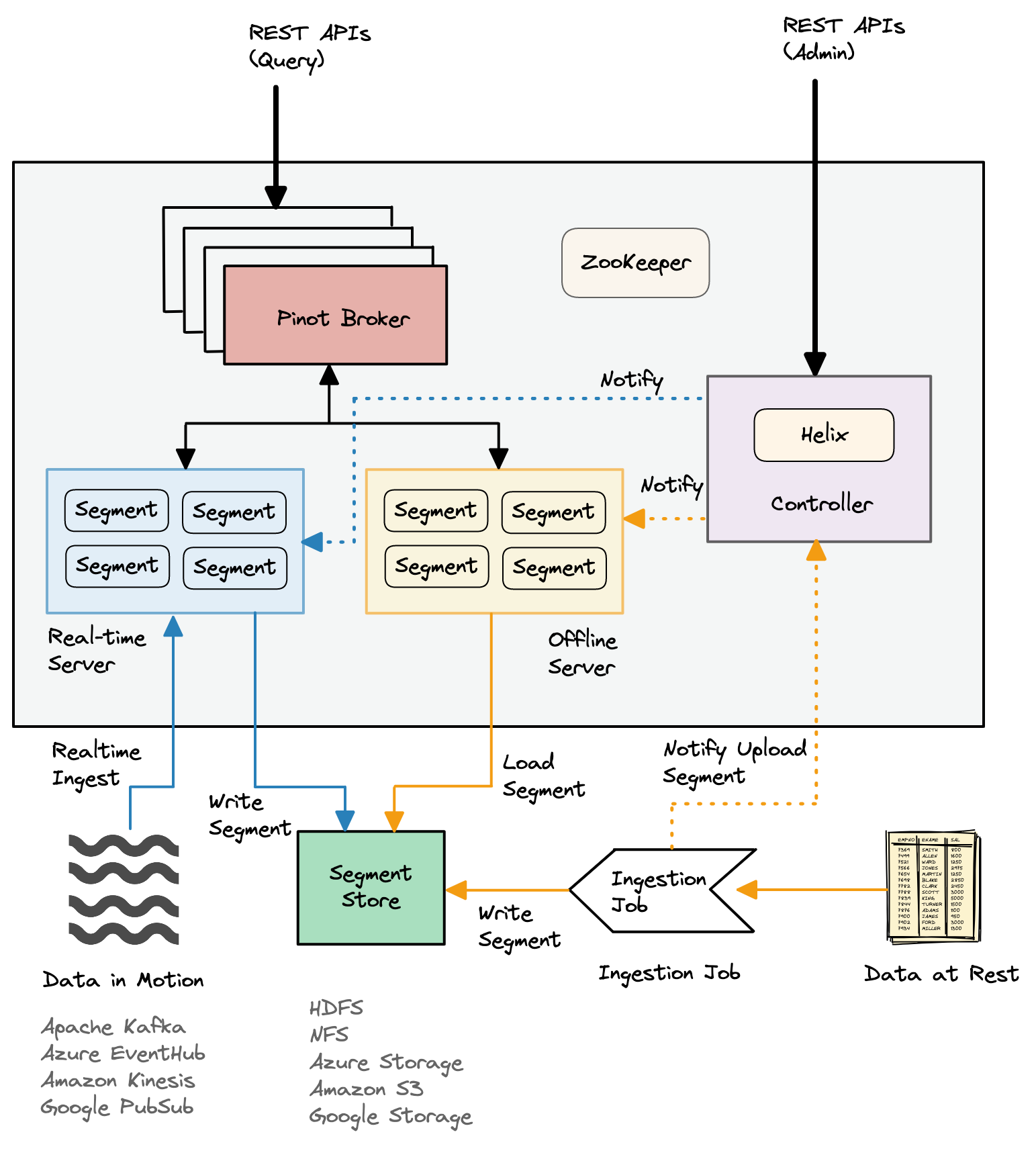 |
|
|---|---|
| Figure 1: Pinot Architecture. |
Ingestion readiness
We can either ingest offline data or realtime data into Pinot. To get both offline and real-time data into Pinot, we need:
- Pinot schema
- Pinot table configuration
- Ingestion job spec
Pinot schema
Schema is used to define the names, data types, and other details for the columns in a Pinot table.
The Pinot schema is composed of:
- schemaName - Defines the name of the schema. Most of the time, this is the same as the table name.
- dimensionFieldSpec - A dimensionFieldSpec is defined for each dimension column. Dimension columns are typically used in slice-and-dice operations such as
GROUP BYandWHERE. - metricFieldSpec - A metricFieldSpec is defined for each metric column. Aggregation is done with the help of metric columns. In the dialect of a data warehouse, these can also be called fact or measure columns. Some operation for which metric columns are used:
- Aggregation -
SUM,MIN,MAX,COUNT,AVG, etc. - Filter clause such as
WHERE
- Aggregation -
- dateTimeFieldSpec - A dateTimeFieldSpec is defined for the time columns. Note that there can be multiple time columns in a table, but only one of them can be treated as primary. The primary time column is used by Pinot to maintain the time boundary between offline and real-time data in a hybrid table and for retention management. A primary time column is mandatory if the table’s push type is
APPENDand optional if the push type isREFRESH. Common operations that can be done on time column:GROUP BYandWHERE.
Pinot doesn’t have strict rules about which of these categories these columns belong to. Instead, you can think of the categories as indications that Pinot can use to do internal optimizations. When we do segment merges and rollups, the categories are also important. Pinot uses the time and dimension fields to figure out which records to merge or roll up.
Data types
Data types determine the operations that can be performed on a column. Pinot supports the following data types:
INTLONGFLOATDOUBLEBIG_DECIMALBOOLEANTIMESTAMPSTRINGJSONBYTES
No explicit type exists for lists or arrays: Pinot also works with columns that have lists or arrays of items, but there isn’t a specific data type for these lists or arrays. We can instead say that a dimension column can take more than one value.
Sample schema
Here’s an example of a Pinot schema for an employee table:
{
"schemaName": "employee",
"dimensionFieldSpecs": [
{
"name": "id",
"dataType": "LONG"
},
{
"name": "name",
"dataType": "STRING",
},
{
"name": "age",
"dataType": "INT",
}
],
"metricFieldSpecs": [
{
"name": "salary",
"dataType": "DOUBLE",
"defaultNullValue": 0
}
],
"dateTimeFieldSpecs": [
{
"name": "createdOn",
"dataType": "LONG",
"format": "EPOCH",
"granularity": "15:MINUTES"
},
{
"name": "modifiedOn",
"dataType": "LONG",
"format": "EPOCH",
"granularity": "15:MINUTES"
}
]
}
Pinot table configuration
Now that we know what our schema is, we can use table configuration to set up the table. Table configuration is used to define the table properties, such as name, type, indexing, routing, retention, etc. It is written in JSON format and is stored in ZooKeeper, along with the table schema.
This table definition has the following information at a very high level:
- How Pinot should create segments for this table.
- Required configurations for indexing.
- Table type, which is set to OFFLINE in this case.
Sample table configuration
A sample table configuration for an employee table is shown below. The tableType property shows us that it is an offline table.
{
"tableName": "employee",
"segmentsConfig" : {
"timeColumnName": "createdOn",
"timeType": "MILLISECONDS",
"replication" : "2",
"schemaName" : "employee"
},
"tableIndexConfig" : {
"invertedIndexColumns" : [],
"loadMode" : "MMAP"
},
"tenants" : {
"broker": "DefaultTenant",
"server": "DefaultTenant"
},
"tableType": "OFFLINE",
"metadata": {}
}
Ingestion job spec
So far, we have set up the schema and table configuration. Just one more configuration needs to be made, which is the ingestion job specification. In order to ingest data into Pinot, Pinot requires us to create an ingestion job specification file. The job spec can be in either YAML or JSON format. This spec file tells Pinot about:
- Where to find the raw data
- Where to create the segments
- Other ingestion-related configuration directives
The following is the sample ingestion job spec file:
executionFrameworkSpec:
name: 'standalone'
segmentGenerationJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentGenerationJobRunner'
segmentTarPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentTarPushJobRunner'
segmentUriPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentUriPushJobRunner'
jobType: SegmentCreationAndTarPush
inputDirURI: '$BASE_DIR/rawdata/'
includeFileNamePattern: 'glob:**/*.csv'
outputDirURI: '$BASE_DIR/segments/'
overwriteOutput: true
pinotFSSpecs:
- scheme: file
className: org.apache.pinot.spi.filesystem.LocalPinotFS
recordReaderSpec:
dataFormat: 'csv'
className: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReader'
configClassName: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReaderConfig'
tableSpec:
tableName: 'employee'
pinotClusterSpecs:
- controllerURI: 'http://localhost:9001'
During ingestion, Pinot offers support for various popular input formats. By changing the format of the input, we can cut down on the time it takes to serialize and de-serialize and speed up the ingestion.
The recordReaderSpec property in the ingestion job spec can be used to change the format of the input:
recordReaderSpec:
dataFormat: 'csv'
className: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReader'
configClassName: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReaderConfig'
configs:
key1 : 'value1'
key2 : 'value2'
The config consists of the following keys:
dataFormat- Name of the data format to consume.className- This class is used for parsing the data.configClassName- This class is used to parse the values mentioned inconfigs.configs- Key value pair for format specific configs. We can skip this config.
For more details about the job spec properties, refer here.
Data ingestion
As mentioned above, Pinot supports a number of popular input formats when it comes to ingesting. Here are the input formats that can be used:
- CSV
- JSON
- Thrift
- AVRO
- Parquet
- ORC
- Protocol Buffers
Refer the official documentation here to learn more about how to configure the properties of input formats.
Ingesting offline data
Offline ingestion stores data in offline tables that are kept separate from realtime tables. Segments for offline tables are constructed outside of Pinot, usually in Hadoop via map-reduce jobs and ingested into Pinot via REST API provided by the Controller. Pinot has libraries that can create Pinot segments from input files in AVRO, JSON, or CSV formats in a Hadoop job and send them to the controllers via REST APIs.
When an offline segment is ingested, the controller looks up the table’s configuration and assigns the segment to the servers that host the table. Depending on how many replicas are set up for that table, it may put more than one server in charge of each segment.
Note: Pinot supports different segment assignment strategies that are optimized for various use cases.
Once segments are assigned, Pinot servers get notified via Helix to host or serve the segment. The segments are downloaded from the remote segment store to the local storage, where they are untarred/unzipped and mapped to memory. Helix lets brokers know that these segments are available once the server has loaded (memory-mapped) them. The brokers start to add the new segments for queries.
Offline data segments are immutable: Data in offline segments are immutable (rows cannot be added, deleted, or modified). However, segments may be replaced with data that has been changed.
Pinot supports uploading offline segments to real-time tables. This is helpful when a user wants to start a real-time table with some initial data.
Ingesting realtime data
When realtime data is ingested, it is stored in realtime tables. Pinot servers ingest rows from data streams like Kafka and use them to build segments for realtime tables. As soon as a row is ingested from a stream, it is made available for query processing. This is because events are instantly indexed in memory upon ingestion.
Note: The ingestion of events into the realtime table is not transactional, so replicas of the open segment are not immediately consistent or same.
A pinot table can be configured to use one of two ways to get data from streams:
lowLevel- This is the preferred mode of consumption. Pinot creates separate consumers at the partition-level for each partition.highLevel- Pinot creates one stream-level consumer that consumes from all partitions. Each message consumed could be from any of the partitions of the stream.
In either mode, the rows that are ingested are stored in volatile memory until one of the following happens:
- A certain number of rows are consumed.
- Consumption has been going on for a certain amount of time.
When one of the above limits is reached, the servers do the following:
- Pause consumption.
- Persist the rows consumed so far into non-volatile storage.
- Keep consuming new rows into volatile memory.
The persisted rows form what we call a completed segment. This is different from a consuming segment, which resides in volatile memory.
Explore more like this

Apache Pinot joins hands with Kafka and Presto to provide low-latency, high-throughput user-facing analytics
Apache Pinot is a real-time, distributed OLAP datastore that was built for low-latency, high-throughput analytics, making it perfect for user-facing analytical workloads. Pinot joins hands with Kafka and Presto to provide user-facing analytics.
Jan 15, 2024 - 18 Mins Read
Comments