

Image Credits: Image generated by DALL-E.
Table of contents
What is an algorithm?
An algorithm is a set of steps or instructions in a particular order for performing a specific task.
If we have ever written code before, we have written an algorithm. The code can be considered an algorithm. There are multiple problems in computer science, but some of them are pretty common regardless of the project we’re working on. Different people have developed various solutions to these common problems, and the field of computer science has, over time, identified several that perform well for a particular task.
What characteristics or guidelines do algorithms possess?
- An algorithm should have a clearly defined problem statement, input, and output.
- The algorithm’s steps must be performed in a very specific order.
- The steps of an algorithm must be distinct; it should not be possible to subdivide them further.
- The algorithm should produce a result; each instance of a given input must produce the same output every time.
- The algorithm must finish within a finite amount of time.
These guidelines not only aid in defining what an algorithm is, but also in validating its correctness.
Big-O notation
Big O notation uses algebraic terms to describe the complexity of our code. It describes an asymptotic upper bound i.e., worst case scenario.
No mathematical knowledge is necessary to understand Big-O notation. Each Big-O notation defines a curve’s (XY graph) shape. The shape of the curve represents the relationship between the size of a dataset (amount of data) and the time it takes to process that data.
The performance of the following Big-O notations is ranked from best (`O(1)`) to worst (`O(n!)`). Here, the letter n represents the input size.
- O(1) - Constant complexity that takes the same amount of space regardless of the input size.
- O(log n) - Logarithmic complexity. It’s better than
O(n)and close to that ofO(1). Every timen(input size) increases by an amountk, the time or space increases byk/2. - O(n) - Linear complexity.
- O(n log n) - Log linear complexity
- O(n^2) - Quadratic complexity with a growth rate of
n2i.e.,n x ntimes. - O(2^n) - Exponential complexity
- O(n!) - Factorial complexity
Efficiency of an algorithm
A problem can be solved in more than one way. So, it is possible to come up with more than one solution or algorithm for a given problem. In such a case, we must compare them to determine which is the most effective.
There are two measures of efficiency when it comes to algorithms:
- Time (aka time complexity)
- Space (aka space complexity)
Time complexity (Speed)
The efficiency measured in terms of time is known as time complexity. Time complexity is a measure of how long an algorithm takes to execute. Time complexity is defined as a function of the input size n using Big-O notation as O(n), where n is the size of the input and O is the growth rate function for the worst-case scenario.
Big-O notation: The Big-O notation enables a standard comparison of the worst-case performance (aka upper bound) of our algorithms.
Constant time complexity
If an algorithm’s time complexity is constant, its execution time remains the same regardless of the input size and the number of times it is executed. The constant time is denoted by O(1) in Big-O notation. If we can create an algorithm that solves the problem in O(1), we are likely at our top performance. Note that O(1) has the least complexity.
Space complexity (Memory)
In an algorithm, time is not the only thing that matters. We may also worry about the amount of memory or space an algorithm requires. Space complexity is the amount of memory space that an algorithm or a problem takes during execution. Put simply, it corresponds to the amount of memory a program or algorithm uses. The memory here is required for storing the variables, data, temporary results, constants and many more. In other words, the space complexity is not only determined by the amount of storage space consumed by the algorithm or program, but it also takes into account the amount of storage space required for the input data.
For example, creating an array of size n will require O(n) space. O(n2) space is required for a two-dimensional array of size n x n.
Space complexity vs. auxiliary space
People have a tendency to get space complexity and auxiliary space confused with one another. Let’s get one thing out of the way first: they are two different terminology.
Auxiliary space is the temporary space that our program allocates in order to solve the problem with respect to the amount of data that is supplied as input. Note that the size of the supplied input data does not account for this auxiliary space in any way. However, space complexity includes both auxililary space and space used input data.
Auxiliary space = Total space - Size of input data
Space complexity = Auxiliary space + Size of input data
An efficient algorithm must be able to achieve a balance between both time and space complexity measures. For example, it might not matter if we have a super-fast algorithm if it uses up all the memory we have.
Ideal efficiency: The most efficient algorithm could be one that performs all of its operations in the shortest time possible and uses the least amount of memory.
Linear search algorithm
For a given value of n, linear search will require n attempts to locate the value in the worst case. By evaluating a worst-case scenario, we avoid having to perform the necessary work. We are aware of the actual or potential outcome. As the value gets really large, the running time of the algorithm gets large as well.
What is data structure?
A data structure is a way to organize, manage, and store data that makes it easy to access its values and change them. To efficiently access or utilize data, we must first store it efficiently.
Data structures are essential ingredients in creating fast and powerful algorithms. They make code cleaner and easier to understand.
The following five operations are commonly performed on any data structure:
- Insertion
- Deletion
- Traversal
- Searching
- Sorting
Types of data structure
Generally, data structures fall into two categories:
- Linear data structure
- Non-linear data structure
Linear data structure
Data elements are arranged sequentially in a linear data structure. These elements can be ordered in any manner (ascending or descending). In a linear data structure, each element must have an element before it, and if it is not the last element, it may also have an element after it.
Non-linear data structure
TODO
Asymptotic analysis
Frequently asked questions (FAQ)
Array vs. linked list
Inserting an element at the beginning of the sequential list is way faster in the linked list than in the array.
O(1) vs. O(log(n))
O(log(n)) is more complex than O(1). O(1) indicates that the execution time of an algorithm is independent of the size of the input, whereas O(log n) denotes that as input size n increases exponentially, the running time increases linearly.
In some instances, O(log(n)) may be faster than O(1), but O(1) will outperform O(log(n)) as n grows, because O(1) is independent of the input size n.
What is asymptotic analysis?
Asymptotic analysis is the process of calculating the execution or running time of an algorithm in mathematical units in order to determine the program’s limitations or run-time performance. Using asymptotic analysis, we can determine the worst case, average case, and best case execution times of an algorithm.
Following are the asymptotic notations for each of the three execution time cases:
- Worst case is represented by
Ο(n)notation; represents upper bound. - Average case is represented by
Θ(n)notation aka Big-Theta; represents tight bound. - Best case is represented by
Ω(n)notation aka Big-Omega; represents lower bound.
What are the common approaches for developing algorithms?
There are three common approaches for developing algorithms:
- Greedy approach
- It’s a simple and straightforward approach.
- Identifying a solution by selecting the next component that provides the most obvious and immediate benefit, i.e. the next-best option.
- It identifies the feasible solution, which may or may not be the optimal solution.
- In this method, a decision is made based on the information currently available, without consideration for the long-term consequences.
- Divide and conquer approach
- The divide strategy involves dividing the problem into smaller subproblems until those subproblems are simple enough to be solved directly.
- The conquer strategy solves subproblems by calling recursively until all subproblems have been resolved.
- After resolving all subproblems, combine them to arrive at the final solution for the entire problem.
- The divide-and-conquer approach is often used to find an optimal solution to a problem.
- The standard algorithms that follow the divide and conquer algorithm/approach are listed below:
- Binary search
- Quicksort
- Merge sort
- Closest pair of points
- Strassen’s algorithm
- Cooley–tukey fast fourier transform (FFT) algorithm
- The karatsuba algorithm
- Dynamic programming
- It is similar to the divide and conquer strategy because it divides the problem into smaller sub-problems.
- In dynamic programming, sub-problems are interdependent; therefore, the results of subproblems are stored for future use so that they do not need to be recalculated.
- Before calculating the solution to a current subproblem, the previous solutions are examined. If any of the previously solved sub-problems are similar to the current one, the result of that sub-problem is utilized. Finally, the solution to the original problem is obtained by combining the solutions to the subproblems.
How constant time differs from linear time?
When it comes to time complexity, no matter how big the constant is and how slow the linear increase is, linear will at some point surpass (exceed) the constant.
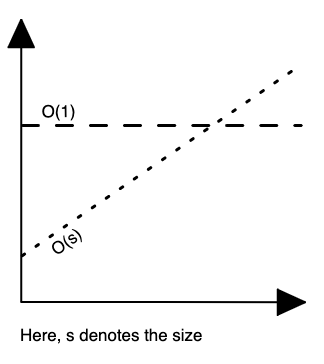 |
|
|---|---|
| Figure 1: Time complexity - O(1) vs. O(s). |
What is amortized time complexity?
Amortized time complexity occurs when an operation is extremely slow once in a while (occasionally) and has expensive worst-case time complexity, but the operations are faster the majority of the time.
In the case of a dynamic array, if its size reaches capacity, it immediately expands to double its original size. For example, if an array’s starting size is 10, and it fills up, the size will be increased to 20.
The following steps are taken when the dynamic array is filled:
- Allocate memory for a larger array size, generally twice the size of the previous array. Its time complexity is
O(2n), wherenis the size. - Copy all the contents of the old array to a new one. Its time complexity is
O(n). - Insert the new element. Its time complexity is
O(1)for each insertion.
What operations are available for stacks?
The operations listed below can be performed on a stack:
- push() - Adds an item to stack
- pop() - Removes the top item in the stack
- peek() - Gives top item’s value without removing it
- isempty() - Checks if stack is empty
- isfull() - Checks if stack is full
Comments